Fake Voices, Real Podcast Problems
Brian Stever
Deepfake Audio Detection · 2026 · PyTorch, torchaudio, ASVspoof, spectrogram CNNs
Abstract. Deepfake Audio Detection started as coursework and immediately wandered into familiar territory: podcast production, where a voice is not just audio but evidence. The project builds a synthetic speech detector around log-Mel spectrograms, a compact CNN with Squeeze-and-Excitation attention, and ASVspoof evaluation data. The final model is fast and genuinely useful as a research prototype. It is also not ready to guard the studio door by itself, which is a much better finding than pretending otherwise.
1.Why Podcast Voices
Podcasting does a strange thing to voices. A host's voice becomes a brand, a relationship, a production cue, and occasionally a shaky little authentication system wearing headphones. If a clip sounds like the right person, everyone is tempted to relax.
Deepfake audio makes that instinct risky. The imagined attacker does not need a movie-villain setup. Public episodes, guest spots, livestreams, or social clips can become source material, and the fake output can arrive looking like one more file in the publishing flow. The detector here is not the whole security plan. It is the extra person in the room asking, politely, whether the waveform seems too confident.
2.Pipeline
The system converts every clip to mono 16 kHz audio, pads or trims it to four seconds, and transforms it into a 128-bin log-Mel spectrogram. The main model treats that spectrogram like a single-channel image and uses a four-block CNN with Squeeze-and-Excitation channel attention.
Training used ASVspoof 2019 Logical Access train/dev data, then evaluation moved to the full ASVspoof 2021 LA set. That jump matters. The friendly split can make a model look like it has been lifting weights. The 2021 benchmark asks it to carry furniture up stairs.

3.Results
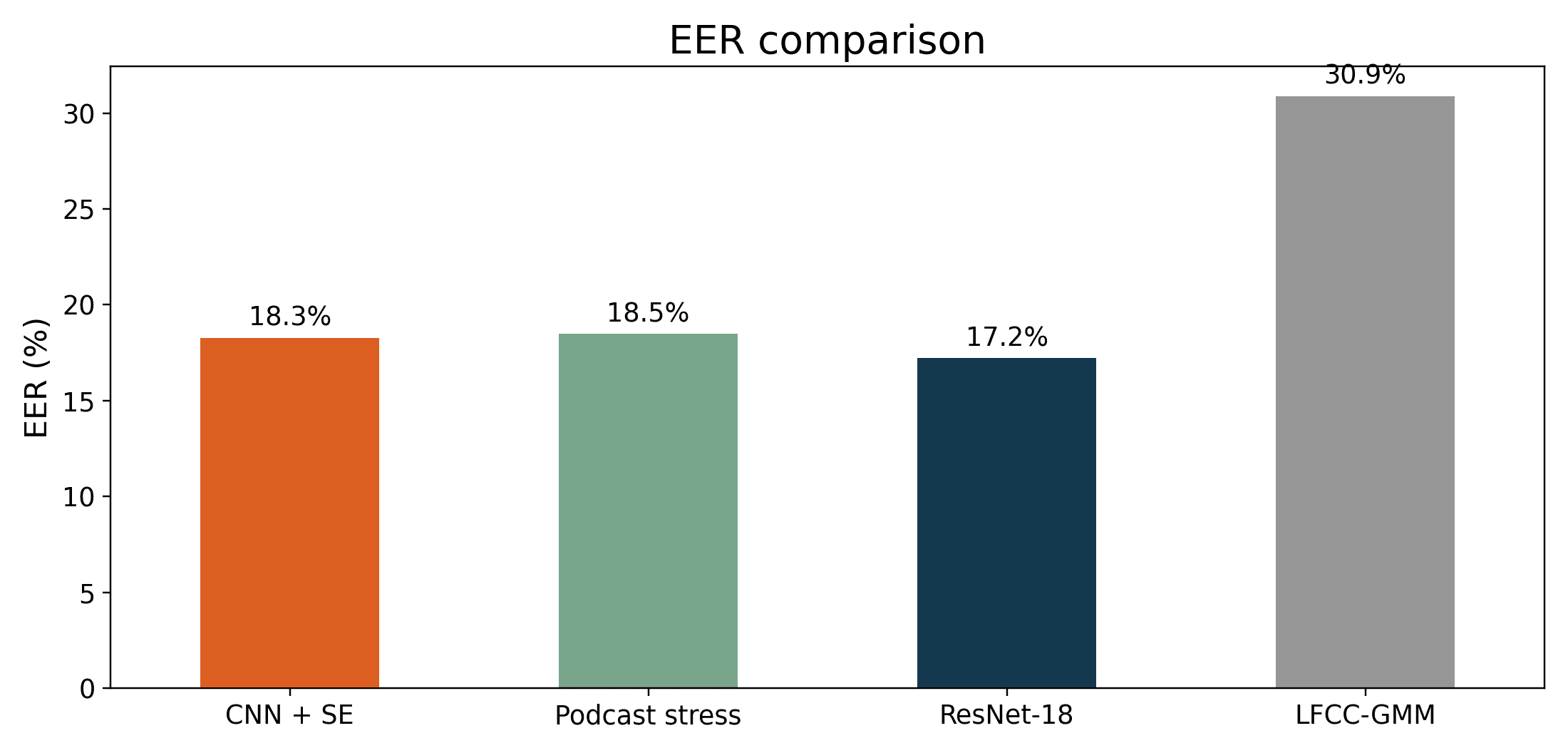
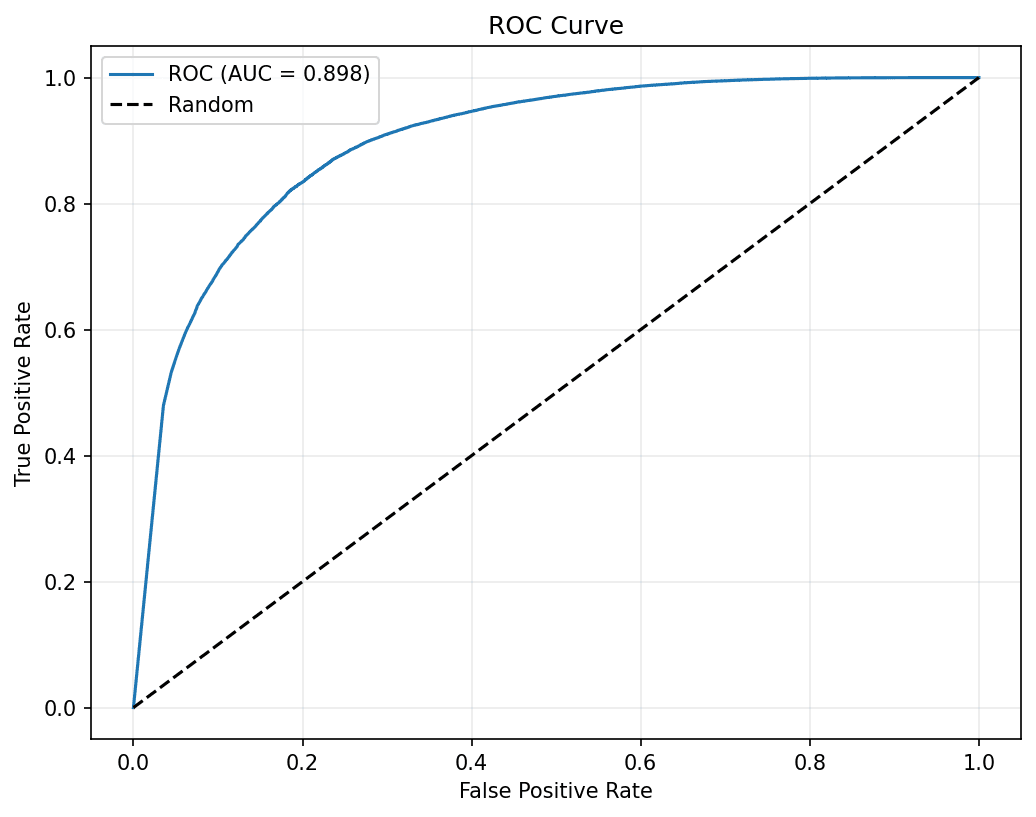
The main CNN + SE model reached 18.28% EER and 0.8979 AUC-ROC on the full ASVspoof 2021 LA evaluation set. At a fixed threshold it had strong F1, but EER is the more security-relevant metric, and it keeps the story honest: working detector, yes; deployable countermeasure, not yet.
A podcast-style stress test added noise, room response, and MP3-like compression. The model got worse, because audio production is where clean signals go to develop personality, but it did not fall apart. EER moved from 18.28% to 18.48%, while AUC dropped from 0.8979 to 0.8852.
Table 1. Selected evaluation results.
| Experiment | EER | AUC | F1 |
|---|---|---|---|
| CNN + SE, clean 2021 LA | 18.28% | 0.8979 | 0.9479 |
| CNN + SE, podcast stress | 18.48% | 0.8852 | 0.9430 |
| ResNet-18 baseline | 17.21% | 0.8957 | 0.9145 |
| LFCC-GMM baseline | 30.89% | 0.7400 | 0.8128 |
4.Baselines and Tradeoffs
ResNet-18 had the best EER at 17.21%, so the smaller model does not get a parade. The more interesting result is practical: the CNN + SE model stayed competitive while using far fewer parameters and running faster in local MacBook timing.
The LFCC-GMM baseline was much weaker at 30.89% EER. That gave the project a useful floor: a traditional cepstral-feature approach was not enough for this version of the task, while the learned spectrogram models handled the benchmark much better.
5.What It Proved
The project worked in the engineering sense: data loading, preprocessing, augmentation, training, checkpointing, baseline comparison, evaluation, plotting, and metric export all ran end to end. It also failed in the useful research sense: the 2021 benchmark exposed a generalization gap that the 2019 development split politely kept hidden.
That is probably the right lesson. A detector can look heroic in the lab and still get weird when codecs, channels, and synthesis systems shift. The next version would need threshold calibration, stronger anti-spoofing architectures, and tests using real podcast export chains from the tools production teams actually touch.